Table of contents
Open Table of contents
스트림 처리 도입 배경
배달 인프라 상황
- 외부 데이터: 기상정보, 교통정보
- 내부 데이터: 지역별 배달/라이더 현황 ..
지역별 배달/라이더 현황을 어떻게 집계할 것인가?
스트림 처리로 전환해야 했던 이유
5년전엔 옳았던 배치처리
- 이벤트가 들어오면 DB에 저장
- 대상 데이터 조회
- 배치처리
- 결과 적재
생긴 문제점들
- 서비스 트래픽이 늘어나며 생긴 대규모 파생 데이터
- 요구사항 증가로 인해 점점 복잡해지는 처리 로직
- 주문 수 편차로 인해 예측이 어려운 처리시간
- ex) 평소엔 1초 이내에 끝나던 배치가 주말만 되면 3분 이상 소요
- 배치 주기에 따라 자꾸 한발 느린 이상탐지
대량의 데이터를 실시간으로 처리해보자
Kafka Streams를 선택한 이유
| 구분 | Apache Flink | Kafka Streams |
|---|---|---|
| 특징 | 독립적인 클러스터 프레임워크 | 표준 자바 애플리케이션 포함 가능한 라이브러리 |
| 배포 및 실행 | Flink 클러스터에 배포하여 별도 작업 실행 | 별도 클러스터 구성 없이 어플리케이션 내에서 실행 |
| 일반적인 담당팀 | 데이터 인프라팀, BI팀 | 비즈니스 애플리케이션 담당팀 |
| 지원하는 서드파티 | 카프카, 카산드라, 다이나모 DB 등 다양함 | 카프카의 매커니즘 활용 |
| 학습 난이도 | 잘 작성된 문서와 다양한 사례로 인해 쉬움 | 직관적이지 않은 문서와 국내 사례 부족으로 인해 어려움 |
Kafka Streams 기본 개념
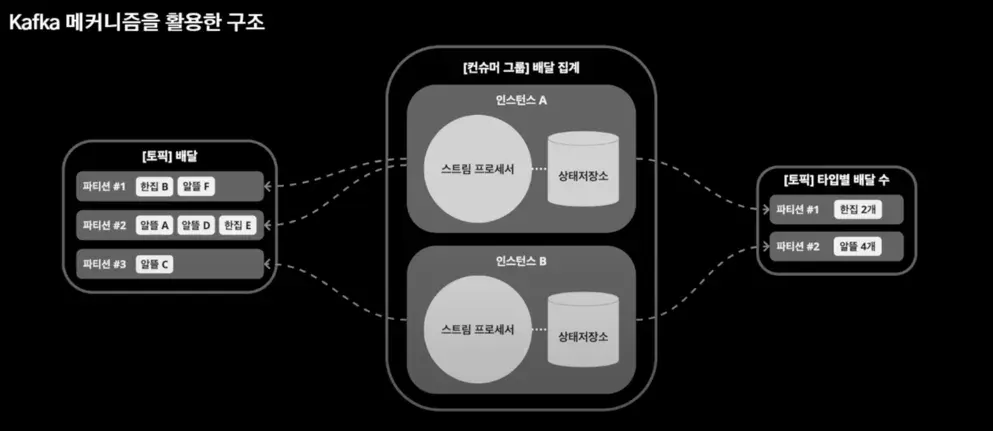
- 스트림 프로세서는 카프카의 컨슈머
- 토픽으로 들어온 데이터를 분산하여 처리
- 스트림 프로세서에 처리 로직이 들어가게 됨
- 처리를 하면서 필요한 상태관리는 상태 저장소라고 하는 로컬 저장소 사용
- 상태 저장소에 집계하여 다음 토픽에 흐르도록 처리
프로그래밍 방식은 DSL(Domain Specific Language)과 Processor API가 있음
도메인 요구사항과 전략
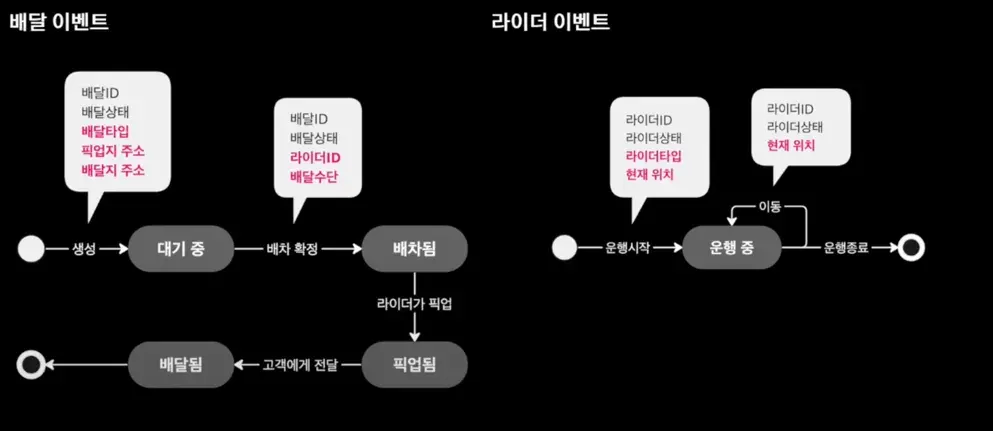
도메인 이벤트
배달 정보에서 상태가 바뀔 때 마다 정보를 append or update
도메인 요구사항
- 배달 + 라이더 이벤트로 특정 라이더 상황 파악
- 행정동 규모의 세분화된 지역별 현황 집계
- 언제 어디서나 데이테 제공 보장
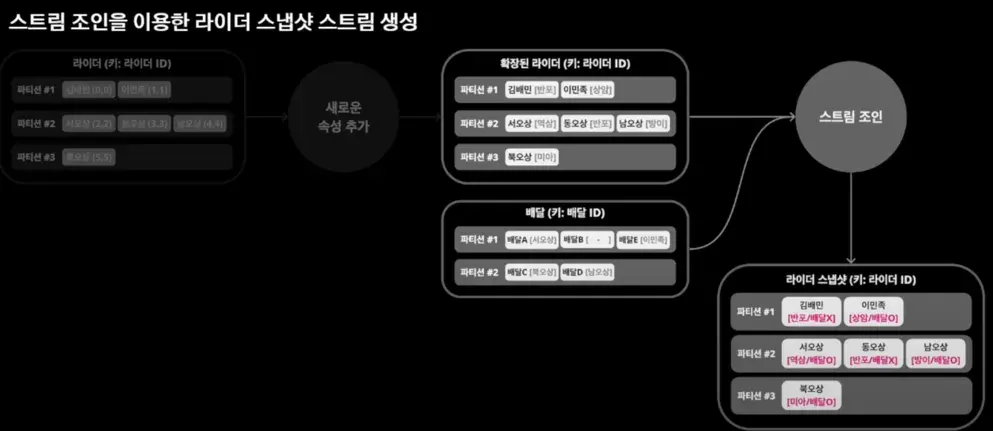
요구사항1: 전처리
새로운 속성을 추가한 확장 이벤트 발행 후 스트림 조인을 이용한 라이더 스냅샷 스트림 생성
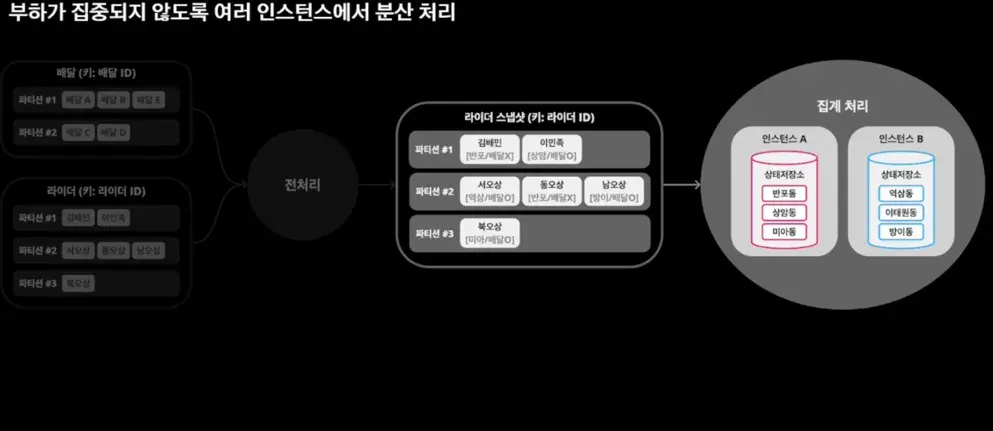
요구사항2: 지역별 데이터 집계
부하가 집중되지 않도록 여러 인스턴스에서 분산 처리
요구사항3: 데이터 제공 보장
- 데이터가 있는 인스턴스로 요청이 들어온 경우 해당 인스턴스에서 처리
- 데이터가 없는 인스턴스로 요청이 들어온 경우 다른 인스턴스로 요청 전달
- 상태 저장소에 접근할 수 없는 경우(인스턴스 다운 등)를 대비하여 백업 저장소 구축
이슈와 해결방안
잦은 메시지 발행 실패
- 브로커&클라이언트 각종 설정값 최적화
- 토픽, 파티션 검토
과도한 토픽 파티션 수
처리속도가 느리다고 파티션 수 증설에 의존하지 말자
- 토픽의 파티션 수는 한번 늘리면 줄일 수 없음
- 파티션은 브로커의 파일 시스템 리소스를 사용하기 때문에, 매우 큰 수의 파티션은 클러스터 전체 성능에 영향을 줄 수 있다.
- 내부 토픽의 파티션 수는 원본 토픽의 파티션 수를 따른다.
-> 적은 수로 시작하여 필요에 따라 늘리는 것이 좋음 -> 파티션 조정을 위한 중간(bypass) 토픽을 만드는 것을 검토
토픽의 단위
하나의 general 토픽에 모든 데이터를 발행 -> 메시지 양이 많아지고 파티션이 점점 더 많이 필요하게 됨 -> 컨슈머는 관심있는 데이터 외에 너무 많은 메시지를 수신받고 필터링하게 됨
토픽을 구분하는 단위는 정답은 없지만 도메인 단위로 구분
리밸런싱과 Lag
서버 배포시 리밸런싱이 발생하는데, 이떄 특정 스트림 프로세서에 Lag이 과도하게 쌓임
컨슈머 Lag - 컨슈머가 읽어야 하는 메시지와 실제로 읽은 메시지의 차이
서버 증설은 한계가 있으므로, 파티션 수와 인스턴스 수를 고려해서 적절한 스레드 수를 설정하자
권장: 파티션 수 = 인스턴스 수 * 스레드 수(num.stream.threads)
리밸런싱
- 컨슈머 그룹내 컨슈머들에게 작업을 균등하게 분배하기 위해, 파티션을 할당을 조정하는 동작
- 파티션 할당 조정이 필요한 경우 일어남
- 대표적으로 토픽 파티션 수 증설, 서버 스케일링, 컨슈머 이슈로 탈락
리밸런싱 동안 컨슈머 처리가 중단되므로 COOPERATIVE 전략으로 한 번에 재조정은 지양
처리 지연으로 인한 컨슈머 그룹 탈락
코드 버그로 인해 처리 지연이 발생하며 컨슈머 그룹에서 탈락됨
- 컨슈머 처리 속도에 따른 적절한 옵션값 설정
- 컨슈머가 폴링 후, 다음 폴링까지 기다리는 시간(
max.poll.interval.ms) - 컨슈머가 한번 폴링할 떄 처리하는 최대 메시지 수(
max.poll.records)
- 컨슈머가 폴링 후, 다음 폴링까지 기다리는 시간(
- 처리 속도와 Consumer Group Leave 로그를 적극적으로 모니터링
- 지연이 발생할만한 부분의 주의(ex. 외부 API 호출)
상태저장소 잘 쓰기
상태 저장소는 내부적으로 토픽이 생성되어 관리됨
Retention, Delete Policy 등을 잘 설정해야 함
리파티셔닝 남용 금지
리파티셔닝은 map()과 같은 새로운 키가 생성되는 메소드 호출시 키 변경에 따라 토픽 파티션을 이동시키는 작업
- 대규모 데이터 이동으로 네트워크/디스크IO 부하 발생 가능
- 가급적 키 변경 연산(
map,transform,flatmap,groupBy) 보다는mapValues,transformValues,flatmapValues,groupByKey등을 사용
스트림 처리 중에는 가급적 외부API/DB 호출을 지양
애초에 이벤트를 풍부하게 구성하거나, KStream/KTable 조인을 통해 처리